
Generative AI Guidance
Introduction

What is AI and Generative AI?
Artificial Intelligence (AI) is a type of programmed or algorithm-based software system that attempts to mimic elements of human intelligence. AI often uses Machine Learning, where a computer is programmed with the intent and capability to recognise, learn and apply new information to a given situation.
Generative Artificial Intelligence (Generative AI) takes what it has learned from its programming - from huge training databases and online information - to create new content. Creations may be in the form of images, video, text, or even music and art, with some Generative AI tools being capable of multimodal creation - that is of creating both texts and images. For example, in the case of text creation, Generative AI systems rely on very large language data sets and use this data to structure and predict how sentences are built, and information can be conveyed.
Both AI and Generative AI use a combination of supervised and unsupervised learning. Supervised learning occurs when humans assist AI learning by providing it with labelled data and known outcomes. In contrast unsupervised learning takes place when AI analyses data to find patterns and structures without human interference.
Not all AI is Generative AI. It is, however, Generative AI that has captured most attention of late and is the domain of AI that has provoked most educational interest.
AI Literacy
It is believed that Generative AI using LLMs assess the words in our prompts, not our sentences or the concepts our sentences might point to. Where humans represent words using letters, AI uses 'word vectors' which are made up of a combination of numbers. The numbers themselves obtain meaning only through their spatial relationship to the other word vectors. To narrow meaning and come up with more precise predictions, Generative AI uses a process called transformation, which reassess the word vectors based on the other word vectors found within your prompt. Each layer of transformation narrows the meaning of each word within your prompt based on probability. Its output then responds to each of these word vectors individually through a process of prediction, predicting the most common words that should be used. This process can lead to errors in the information that it creates and much of this process happens within a 'black box'.
Credit: Queen's University Library (2025) Generative AI Algorithms
Need help visualising this process? Read: How AI chatbots like ChatGPT or Bard work - visual explainer - The Guardian.
Different Generative AIs use different data sources. It is always important to check what data source your chosen AI is using and if it's using up to date content. Many Generative AI platforms are trained on the publicly available content found on the internet. This means it contains bias, misinformation and both credible and uncredible sources.
While some Generative AI platforms reference the materials they use, many don't or are inconsistent in their referencing. As such, it can be difficult to tell with 100% certainty where data has come from. In absence of this, where work is being produced within an educational context, it is very important that you put into quotations and cite any materials produced by Generative AI.
A Generative AI's use of data will depend on the terms and conditions set out by the company that owns the application. Some tools will collect the data that is inputted into them. If you agree to terms of use that give Generative AI access to other data on your device, like your photos, the tool can collect data in this way. Some applications allow you to decide whether you want to have your data included in training for the AI application, and some applications don't collect data at all. The only way to know how your data is being used and collected is to read the terms of use for the applications you use.
Staff wishing to complete the badged version of this offering, GenAI for Teaching and Learning: How to do it right, should please contact LEAD for facilitation.
What are the Possibilities and Limitations?
GenAI has huge potential and can help us with everyday tasks or even more complex processes. It can create written texts, produce videos, compose music, translate language, create artwork, answer math's questions, construct and explain computer code, and analyse data sets by drawing on pre-existing materials and knowledge, provide transcription, create graphic visualisations, manage content, produce podcasts, help with the searching and management of academic resources, help us to study, create clear lesson and study plans, and give feedback.
AI has a huge propensity to learn from data and recognise patterns and relationships. It can manage incredibly large data sets and can process them at a faster speed than a human. This means that AI has the ability to super drive research and scientific advancement.
However, while AI and Generative AI have huge potential, it must be used responsibly and with a clear understanding of its limitations. These limitations include:
To train Generative AI a large data source is needed. As a result, many models have been trained on content found on the internet. This content isn't always reliable and can contain biases. When looking at a Generative AI output we must assess for bias or misinformation. This is important so we don't spread misinformation or perpetuate bias.
Many Generative AIs work on a 'free' model, but this model isn't really free. Instead, in exchange for use, we are providing the model with our data, whether that is through our inputs or the access and permissions we agree to when an AI application is downloaded to our device. It is important that you read the terms and conditions of the applications you are using to ensure that you aren't sharing data that you'd rather not share.
Generative AI is known for working in a 'black box' and for producing unique outputs. This means that it can be difficult for us to monitor how it has come to its conclusions, where its information comes from and it is often impossible to replicate results for reliability. This can make it difficult to spot errors in the outputs we receive.
The outputs from LLM powered Generative AIs often assume the voice of an expert. However, the professional delivery of content can be misleading, as the outputs can often include false information. This can be problematic for non-experts who are still studying their subjects of interest, as the professional tone of the outputs can make errors hard to spot
As Generative AI draws on the data of others without referencing this material, it in a sense plagiarises ideas, concepts and, at times, phrasings. While some Generative AI's make a point of referencing content, these references can at times be fictitious or inaccurate. When using Generative AI we must be conscious that we don't always know where the material has come from. This is why it is very important that we cite the Generative AI we use and make sure that any content that is used verbatim is put within quotation marks and referenced.
As the decision-making process that Generative AIs follow occur within a 'black box', it is difficult to understand, or in some cases impossible to understand how a decision was reached (Read: Generative AI vs. predictive AI: What’s the difference? - IBM). Without this understanding, it can be unclear why Generative AI picks to use particular sources over others. For academic work, this might result in the Generative AI picking an academic source that isn't the most appropriate or recognised within the academic community.
As some Generative AI models are trained on biased information and misinformation, at times Generative AI can produce hurtful content. It is important that you consider your wellbeing and the wellbeing of others when using Generative AI. If you come across something distressing when using Generative AI, please speak to your module lead or Head of Department to be referred to the appropriate supports, or contact Student Life or Counselling Service.
Generative AI has a large environmental impact, as the data centres it runs on requires significant cooling as well as rare metals to be use (Berthelot et al, 2024). Further, as Regilme (2024, p.77) tells us, “A study from the University of Massachusetts Amherst found that training a single AI model can emit over 284,000 kilograms of CO2, equivalent to the lifetime carbon footprint of five cars.” Regilme goes on to highlight that the building of “data centers [by large tech companies] in regions with weak environmental regulations, like the Global South[, have lead to] worsen local environmental degradation and natural resource depletion in areas already heavily impacted by climate change.” (Regilme, 2024 p.77)
In order for Generative AI to stay current and relevant, it must be fed with data. If you are using a model that is out of date, the outputs from the model will be less relevant. It is important that you check to ensure that the tools you are using are up-to-date.
According to Regilme (2024, p. 76) ‘Major tech companies, largely in the Global North, outsource tasks like data labeling and content moderation to countries such as India, Kenya, and the Philippines. Workers in these regions, earning as little as $1.50 per hour, face precarious conditions with minimal social safety protections. This exploitation is a deliberate strategy to maximize profits while minimizing costs, at the expense of vulnerable populations.’
References
Adobe. (2025). Firefly (12 September). Image Generation. Adobe Firefly
Berthelot, A., Caron, E., Jay, M., & Lefèvre, L. (2024). Estimating the environmental impact of Generative-AI services using an LCA-based methodology. Procedia CIRP, 122, 707-712.
Credit: University of Galway Library for 'Possibilities and Limitations' section.
Regilme, S.S.F. (2024). Artificial Intelligence Colonialism: Environmental Damage, Labor Exploitation, and Human Rights Crises in the Global South. SAIS Review of International Affairs 44(2), 75-92. https://dx.doi.org/10.1353/sais.2024.a950958.

Except where otherwise noted, content on the LEAD section of this website is licensed under a Creative Commons Attribution 4.0 International licence.
Responsible Use in Teaching, Learning and Assessment
As Generative AI becomes more embedded in society, our working lives and the everyday applications we use, there is a need to reflect on how and where Generative AI might be appropriately incorporated in our courses and in our use. In this section, we will review what acceptable use might look like for staff and students, and give tips and guidance on how Generative AI can appropriately be incorporated in our everyday use.
Generative AI Use Case Scenarios
There are a variety of ways that Generative AI can be used as a study tool. It is important, when considering these uses, that you consult with your lecturer. If you are in doubt about whether your intended use is appropriate, speak with your lecturer first.
If you are planning to use Generative AI as a study tool, ensure that you aware and cautious about what personal data you input or share with an AI system. Where ever possible, make use of institutionally approved and secure AI systems. Before making use of any AI system, please read the Data Compliance section on this page.
The outputs from LLM powered Generative AIs often assume the voice of an expert but their outputs often include false information. This can be problematic for non-experts who are still studying their subjects of interest, as the professional tone of the outputs can make errors hard to spot. Students should be mindful of this prior to using an LLM powered Generative AI to aid their study. The below recommendations for possible AI use are subject to approval from your lecturer::
Generative AI can be used to check for errors in spelling, punctuation, syntax, and/or incorrect word choices.
You can consult with Generative AI to get feedback on the structuring of your assignment or to get recommendations of how you might arrange your ideas and arguments within a skeleton structure.
Use Generative AI to help you develop a work schedule and time management plan for your academic work.
Try using AI to get feedback on your assignment, particularly around the clarity of your writing.
AI can be used as a study aid for exams or tests by having it develop mock exams and quizzes for you.
AI can be used to create podcasts based on your weekly academic readings. These podcasts will allow you to engage with scholarly ideas by listening on your commute, when at the gym or when out for a walk.
Using AI-powered research tools like Research Rabbit can enable you to find new sources and organise your source materials.
AI can help you to check that your references are properly formatted.
AI can take information that you may wish to present in another form and transform it into a graphic representation. Just don't forget to reference it!
Remember, while Generative AI can be a helpful tool, it is not always reliable. Be sure to prioritise your own academic judgement, the academic judgement of your lecturer and the scholarly works you have engaged with over a Generative AI output.
Data Compliance
As we move forward and come into compliance with the EU AI Act, we must begin by questioning how we ensure transparency, fairness, lawfulness and individual rights are upheld in our use of AI systems. Centrally, we need to assess how security is maintained, GDPR is upheld, and fundamental rights are protected.
Use of AI must be compliant with GDPR principles. This means staff and students cannot input MIC data or the personal data of staff or fellow students into AI systems without written prior consent.
Examples of personal data include:
- Staff or student voice recordings (e.g., lecture audio, interviews)
- Images of staff or students (e.g., classroom photos, ID scans)
- Lecture slides and teaching materials created by MIC staff
- Internal publications or research outputs not publicly released
- Fellow students’ assessments, essays, or project work
- Any identifiable information from MIC systems (e.g., student ID numbers, email addresses, attendance records)
Outside of College use, if staff and students decide to make use of AI systems for personal use, they should be aware and cautious about what personal data they give to AI systems - either through inputting the data directly or by agreeing that an AI application can access and harvest data from other applications on their device. Staff should not use unapproved AI systems on their work devices. Within the context of the College, staff and students should make use of institutionally approved and secure AI systems. Use of any other AI system requires prior approval from ICT Services, and a Data Protection Impact Assessment (DPIA) must be completed in consultation with the Information Compliance Office (ICO). Before making use of any AI system, please read the Data Compliance section on this page.
Staff and students should seek to ensure that their use of data does not infringe on the fundamental rights of others. This means avoiding AI use that promotes bias, discrimination, or misuse of personal or institutional data.
Staff and students should not engage in the following prohibited AI practices under Article 5 of the EU AI Act.
Examples may include:
- Academic misconduct
- Privacy Breaches
- Unapproved automated decision-making
- Surveillance & Monitoring
- Bias and Discrimination
- IP Infringement
- Security Risks
To ensure compliance with the EU AI Act we must manage our risk when making use of AI systems. The following steps should be undertaken:
1. Staff must assess whether using an AI product or system is appropriate for the task we need to undertake and that the associated processing of personal data with a chosen AI system is compliant with GDPR.
2. A Fundamental Rights Impact Assessment (FRIA) should be undertaken where MIC is a data controller and the AI product being used relies on personal data. Article 27: Fundamental Rights Impact Assessment for High-Risk AI Systems | EU Artificial Intelligence Act
3. Processes to enable data subjects’ rights, especially if personal data is being put into an AI system, must be in place. MIC must consequently know where the personal data is going and how it is being processed when it is inputted into an AI system. Public AI tools (e.g., ChatGPT, Gemini, Claude) must not be used with MIC data unless authorisation has been granted and an approved DPIA is in place. Staff seeking to use public AI Tools must obtain ICT/ICO approval first. Explicit consent is required before inputting any personal data into an AI system.
4. Where MIC is a data controller, there must be the facility to access, correct or delete personal data that has been put into an AI system if requested by a data subject.
5. Where AI is being proposed for use in automatic decision making, approval must be sought, a DPIA must be completed, legal or significant effects must be assessed, and where AI-informed automatic decision-making is being used, this use must be made transparent.
6. Data use must conform to data minimisation principles, this means that personal data must be processed only for the specific purpose set out in the relevant DPIA or privacy notice.
7. Risk Management: High-risk AI systems require rigorous risk management practices, including impact assessments and continuous monitoring to identify and address potential risks.

High-risk systems have been categorised by the European Parliament (2023, n.p.) as:
1. AI systems that are used in products falling under the EU’s product safety legislation. This includes toys, aviation, cars, medical devices, and lifts.
2. AI systems falling into specific areas that will have to be registered in an EU database:
- Management and operation of critical infrastructure
- Education and vocational training
- Employment, worker management and access to self-employment
- Access to and enjoyment of essential private services and public services and benefits
- Law enforcement
- Migration, asylum, and border control management
- Assistance in legal interpretation and application of the law.
Examples of high-risk AI systems in MIC may include AI systems used in:
- Recruitment or admissions: e.g. automated CV screening tools or university application scoring systems.
- Grading or academic evaluation: e.g. tools that automatically assign grades or assess student performance.
- Biometric identification: e.g., facial recognition for attendance tracking or access control.
- Health or psychological profiling: e.g. tools that analyse student behaviour or mental health indicators.
- Financial decision-making: e.g. systems that determine eligibility for scholarships or funding.
- Surveillance or monitoring: e.g. classroom monitoring tools that track engagement or behaviour.
These systems must undergo formal risk assessments and be subject to continuous oversight to ensure they do not infringe on individual rights or institutional obligations.
8. Transparency and Documentation: Documentation of the data processing activities, including the sources of data, preprocessing steps, and any transformations applied must be kept. Staff must conform to retention periods and deletion requirements for processed personal data. This helps in auditing and verifying compliance.
9. Compliance with the General Data Protection Regulation (GDPR) is essential. AI systems must be designed to protect personal data and ensure privacy by default and by design. Users of AI systems must ensure that their use aligns with GDPR. Where approval has been obtained and DPIAs have been completed, appropriate privacy notices for participants whose data is being processed by AI must be provided to participants. This includes obtaining explicit consent from individuals whose data is being used within an AI system. Information Compliance Office I Staff Portal
10. When using AI, staff should assess and mitigate against biases in the data to prevent discriminatory outcomes. This involves regular monitoring and testing the AI system you are using to ensure fairness and equity.
11. Those wishing to use AI technology within their work at MIC need to be compliant with the ICT Security Policy and the Information Security Policy. As stated in the ICT Security Policy:
8.0 Software
- Only licensed authorised software may be used on ICT equipment or on the ICT network.
- Users should not download, install or use unauthorised software programs. (7)
10.0 Data Protection
It is the responsibility of each member of staff to be diligent in fulfilling obligations in relation to data protection. Data that is not considered public information should not be saved on non-MIC owned devices or public cloud offering that do not meet the standards required by ICT Services. If in doubt consult ICT Services. (8-9)"
Further as stated in the Information Security Policy:
Authorisation Process for Information Processing Facilities
The purpose of this section is to protect all of the information assets within Mary Immaculate College by authorising any new information facility for purpose and use, compatibility of hardware and software, and security of personal information in the facility.
The authorisation process for new Information Processing Facilities requires that the Director of Information Governance and Compliance Management DIGCM (DataProtection@mic.ul.ie) perform a risk assessment prior to authorising a new Information Processing facility.
The results of the risk assessment will be incorporated to establish additional controls by Mary Immaculate College. (5.1.2)"
The Information Compliance Office and ICT are responsible for the monitoring and enforcement of compliance with these policies. With this in mind, staff looking to make use of AI systems and applications should contact the Information Compliance Office to complete a Data Protection Impact Assessment and ICT.
12. Staff looking to use AI need to comply with the AI Public Sector Guidelines.
- Students use of AI must be compliant with GDPR principles. This means that they cannot input MIC data (e.g. lecture recordings, assessments, PowerPoint slides, other academic resources provided by MIC) or the personal data of staff or fellow students, including the recording of staff or student voices or images, staff lecture slides and materials, publications or fellow students' assessments into AI systems without written prior consent. Students who fail to comply with this will be in violation of the Student Code of Conduct, the Electronic Copyright Material Policy and the Data Protection Policy, and could face sanctions.
- While if independently students decide to use AI systems, the College would advise students to educate themselves about the data use agreements they make with any AI system that they intend to use. While the College would not advise students to input their personal data into an AI system, if a student, independently of College advice, decides to do so, they should be aware and cautious about what personal data they give to AI systems, either through inputting the data or by agreeing that an AI application can access and harvest data from other applications on their device. When seeking to use AI systems within the College or for College work, students should refer to the Academic Integrity Policy I College Policies.
- Students should seek to ensure that their use of data does not infringe on the fundamental rights of others. This means that students should not use AI in a way that promotes bias, discrimination and data misuse.
References
Christakis, T. & Karathanasis, T. (2024). Tools for Navigating the EU AI Act: (2) Visualisation Pyramid. MIAI Articles. Retrieved from AI-Regulation website
European Parliament, EU AI Act: first regulation on artificial intelligence, 08 June 2023. [Online]. Available: EU AI Act website
Except where otherwise noted, content on the LEAD section of this website is licensed under a Creative Commons Attribution 4.0 International licence.
Generative AI Infringements
Academic Misconduct and Generative AI
When using Generative AI students must adhere to the Academic Integrity Policy, which includes the appropriate use of sources and technology, including the use of technical assistance in assignments where it has not been authorised. This is captured in the following section of the MIC Academic Integrity Policy:
1.1 Academic Dishonesty Includes: […] using technical assistance in assignments where it has not been authorised, e.g. using translation software in a translation assignment.
2.1 Plagiarism is defined as the use of either published or unpublished writing, ideas or works without proper acknowledgement.
2.3 All writing, ideas or works quoted or paraphrased in an academic assignment in MIC must be attributed and acknowledged to the original source through proper citation.
If a student's use of Generative AI is in violation of the Academic Integrity Policy, and aligns with the policy's definition of plagiarism or academic dishonesty, the student will have engaged in academic misconduct.
Students cannot be penalised for academic misconduct when appropriately citing the use of GenAI.
Students may incur a grade penalty if prior communication has been issued to them advising that GenAI cannot to be used for a particular assessment or in a particular way within the assessment.
AI Misconduct Case Scenarios
You will find five AI misconduct scenarios at the link below. Flip each card to see what violation occurred for each case and why it is considered a violation.

Knowing Boundaries of Use - "When in doubt, ask"
Knowing where and when AI and Generative AI tools can and can't be used can be tricky. Permitted use may vary from module to module and discipline to discipline, depending on the learning objectives that need to be met. If you are not sure what you are allowed to use, you should speak to your lecturer to ask. Remember, when in doubt, ask!
Academic Integrity Interactive Quiz
MIC’s Academic Integrity Quiz is designed to help you test your knowledge and understand best practices that are in line with the MIC Academic Integrity Policy.

Except where otherwise noted, content on the LEAD section of this website is licensed under a Creative Commons Attribution 4.0 International licence.
Considerations for Grading in the context of GenAI
Policy Considerations
There is currently no policy in the College that prohibits students from using generative artificial intelligence (GenAI), if its use aligns with the values of academic integrity. Therefore, students are required to adhere to the Academic Integrity Policy, which includes the appropriate use of sources and technology, including the use of technical assistance in assignments where it has not been authorised. This is captured in the following section of the MIC Academic Integrity Policy:
- Academic Dishonesty Includes: […] using technical assistance in assignments where it has not been authorised, e.g. using translation software in a translation assignment.
- Plagiarism is defined as the use of either published or unpublished writing, ideas or works without proper acknowledgement.
- All writing, ideas or works quoted or paraphrased in an academic assignment in MIC must be attributed and acknowledged to the original source through proper citation.
Students cannot be penalised for the appropriately cited use of GenAI, unless prior communication has been issued to them advising that GenAI was not to be used for a particular assessment.

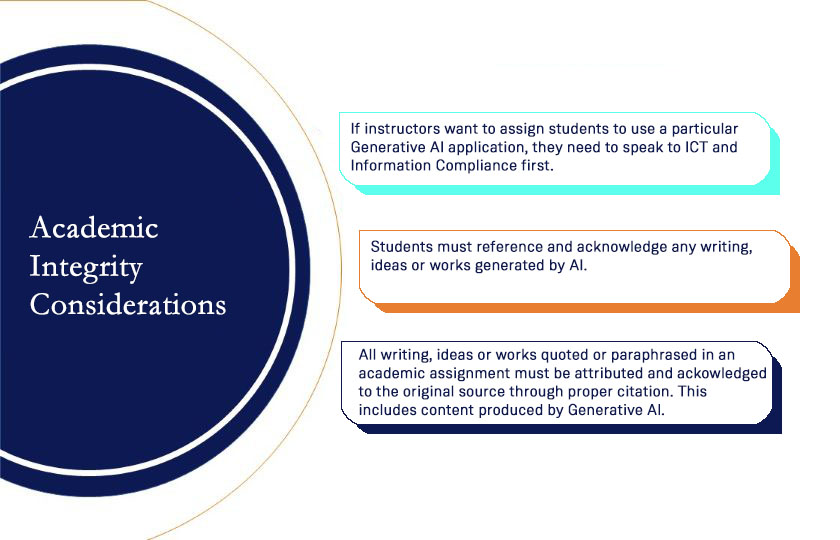
Academic Integrity Considerations
Students are bound by the principles of academic integrity to ensure that all writing, ideas, or works quoted or paraphrased in an academic assignment must be attributed and acknowledged to the original source through proper citation. This includes content produced by GenAI. In the case where students are required to use a particular GenAI application as part of an assessment task, it is recommended that students are directed towards institutionally approved tools. The use of applications which are not institutionally licensed should be discussed with ICT Services and the Information Compliance Office. Consideration should be given to the ethical access to GenAI and sustainability concerns surrounding the use of AI technology.
Considerations Relating to Suspected Breaches of the Academic Integrity Policy
While there are many applications which claim to ‘detect’ the use of GenAI on the market, these are not reliable (see for example, Dalalah & Dalalah, 2023 and Perkins et al, 2024). Such tools can produce false positives and false negatives, meaning that human-produced content can be marked as generated by AI, or vice-versa. Detectors cannot be used as reliable evidence in a circumstance where the unauthorised use of GenAI is suspected. The College does not support the use of any such tools. Students' assignments and data should not be submitted to third party applications without consulting with the College and without obtaining the student’s consent.
The unauthorised use of GenAI can be challenging to identify. However, the following may be indicators:
- Context-inappropriate vocabulary or jargon.
- Outdated or non-existent references.
- Fabricated references.
- References that include journal or book links that link back to a Generative AI writing platform.
- Inconsistent regional language patterns i.e. switching between Irish and American English.
- Hallucinations, which are outputs that are nonsensical or false.
- Suspicious file meta-data.
It is important to remember that just because an assignment looks formulaic or uses words we might associate with GenAI, it does not automatically follow that the submission has been produced by GenAI.
However, if a student's assessment submission contains indicators of the use of GenAI, without any citation of the use of GenAI tools, then there may be a case for further investigation for a breach of the MIC Academic Integrity Policy. In such instances, the agreed procedures for reporting suspected breaches should be followed, as outlined in the MIC Code of Student Conduct.

Except where otherwise noted, content on the LEAD section of this website is licensed under a Creative Commons Attribution 4.0 International licence.
Key Terms
Agents can be autonomous (acting without the control of a human) or semi-autonomous (acting with human oversight). They can make decisions and perform tasks to achieve the objectives they are set. (UMA, n.d.; MIT, n.d.; CTLT, n.d.)
An AI system that can adapt or take action to support the completion of specific tasks. For example, an agentic AI assistant might offer to provide the Chair of an online meeting with summary notes to help them draw the meeting to a close. (UMA, n.d.)
A computer system that undertakes tasks and activities that humans traditionally undertook, using language, image recognition and decision making. (UMA, n.d.; Goff, & Dennehy, 2023; UofS, n.d.)
An AI tool that seeks to help the user to improve grammar, spelling and syntax without generating new material/rewriting the text. (UMA, n.d.)
Software that seeks to identify patterns that might suggest that AI-generated content has been used. These systems are untrustworthy, creating both false positives and false negatives. They also offer no concrete evidence to assess and prove misconduct has occurred.
An approach to the use of AI that seeks to take responsibility for the ethical concerns surrounding the relationship between AI and bias, misinformation, the environment, academic integrity, data management and privacy. (UofS, n.d.; UMA, n.d.)
Algorithms take shape as mathematical formulas or a set of specific instructions, used in computer science or mathematics for the completion of tasks and solving of problems. (UofS, n.d.; Goff, & Dennehy, 2023; MU, n.d.)
A process whereby discriminatory or prejudiced content is produced as a result of systematic errors in the machine learning algorithms used/designed. (UofS, n.d.; Goff, & Dennehy, 2023; UMA, n.d.; CTLT, n.d.; MIT, n.d)
The content an algorithm produces. In the case of Generative AI, this includes the images, audio, text and data that Generative AI creates. (UofS, n.d.)
These models seek to analyse data to identify patterns and relationships that can be found within a given dataset. These models can help to give insight into various trends and happenings. (UofS, n.d.)
Annotation occurs when data is labelled through a process of categorisation. Annotated data-sets are used to support AI to understand patterns and relationships, and can be used to help AI to analyse content or generate new content. (CTLT, n.d.)
The attribution of human-like behaviours, qualities or characteristics to AI or Generative AI systems. (MIT, n.d.)
Artificial General Intelligence (AGI) is a theoretical AI that demonstrates the same cognitive abilities as humans, including but not limited to, critical thinking, reasoning, comprehension and perception. Theoretically AGI will perform the same intellectual tasks that humans do. (CTLT, n.d.; MU, n.d.)
Artificial Super Intelligence (ASI) is a theoretical AI that demonstrates advanced intelligence that will vastly exceed human intelligence. (CTLT, n.d.)
Stereotypical and regressive representations that occur, in the context of AI, when the training data used contains prejudiced data or when the algorithms used perpetuate discriminatory content. (UofS, n.d.; Goff, & Dennehy, 2023; CTLT, n.d.; MIT, n.d)
A software application that performs tasks that are automated. These tasks can be simple or complex. (CTLT, n.d.)
A type of prompt which outlines the step-by-step process for reasoning an AI model should follow before producing its output. This technique is used to improve the accuracy of the AI output. (MIT, n.d.)
When an AI Model outlines the process it followed and the decisions it made to produce its output. (CTLT, n.d.)
A software application that can simulate human conversation. It can be a simple system that is highly supervised, using rules and parameters to provide pre-determined outputs or it can be powered by AI technology to support more complex and context specific discussions. All chatbots use Natural Language Processing, and increasingly, machine learning. (UofS, n.d.; UMA, n.d.; CTLT, n.d.)
The content or result that is produced in response to a prompt or the processing of data submitted to an AI system. These can take shape in a variety of forms (including but not limited to text, audio, images, codes). The quality of the results or content produced is informed by the quality of the prompt, the algorithms used, the training data, and the task being undertaken. (UofS, n.d.; CTLT, n.d.)
The cost of maintaining infrastructure, hardware, software and operations for computer systems. (UMA, n.d)
The scale of text, when represented in tokens, that an AI Model can process at one time. Like a working memory, the size of the context window informs how long a conversation can be, before aspects of the conversation are lost. It also dictates the size of attachments, documents or code that the model can process. (Gergmann, 2024; MIT n.d.)
Combining natural language processing and machine learning, this AI can process language and respond conversationally. Many chatbots and digital assistants use this technology. Some models also use speech recognition and can engage in spoken conversation. (CTLT, n.d.)
The process of converting everyday information into a digital data format. (UofS, n.d)
The manipulation of data, using AI to produce realistic, but ultimately fake media content such as videos or audio. (UofS, n.d)
This subset of machine learning uses three or more layers (sometimes thousands of layers) of neural networks to identify patterns, relationships and features. The training can use unsupervised learning, which sees the deep learning models use raw data without the need for labelling. Deep learning models can evaluate their outputs and, where needed, refine them for accuracy. (Holdsworth & Scapicchio, 2024; UofS, n.d.; UMA, n.d.; Goff & Dennehy, 2023)
Using AI tools to research topics in greater detail and at greater speed than what can be completed through human effort alone. (UMA, n.d)
Ethical use of artificial intelligence requires a consideration of the responsible use of this technology, including protecting against bias, ensuring data protection is upheld, responsible management of data, engagement with quality control and transparency, upholding academic integrity, accounting for human wellbeing in the academic and broader community and environmental impacts. (UMA, n.d; UofS, n.d.)
Skills that language models demonstrate which were not foreseen or expected. (MIT n.d.)
Fairness in AI refers to the responsibility of the programmers and users to ensure that systematic discrimination does not take place and that groups or individuals do not receive inequitable treatment as a result of AI use. (UofS, n.d.)
A type of machine learning where limited training data is used for the AI system to learn from in order to make predictions and decisions. (UMA, n.d; CTLT, n.d.)
Separate from the initial training of a model, tuning is the process in which a model's parameters are refined using more specific data or performance objectives, to improve the model's performance of a specific task. This allows it to have a broad base of knowledge as well as training in a targeted area. For example, a large language model might be fine-tuned on inclusive education scholarship to support educators in a more targeted way. (UMA, n.d; CTLT, n.d.)
This artificial intelligence framework simultaneously uses generator and discriminator neural networks. The generator network creates new fake data that mimics the training data that both neural networks were trained on, while the discriminator evaluates the data to establish which is the real training data and which is the data falsely produced by the generator. (UofS, n.d.)
Generative AI is a type of Artificial Intelligence that can identify patterns and relationships in existing training datasets, and use this information to create new content. Depending on the model, the outputs can be text, images, videos, audio or code. While some Generative AI uses a single mode, others are multimodal. (UofS, n.d.; Goff, & Dennehy, 2023; UMA, n.d.; CTLT, n.d.; MIT, n.d)
Used in natural language processing, Generative Pre-trained Transformers use transformer architecture to process text and generate human-like outputs. The pre-training allows these models to identify patterns and relationships in language in order to make more accurate predictions. (CTLT, n.d.)
Caused by bias in the data or algorithm used by the AI model, insufficient training data, or errors in predictions. Hallucinations happen when an AI model produces false, inaccurate or illogical outputs. (UofS, n.d.; Goff, & Dennehy, 2023; MU, n.d.; CTLT, n.d.; MIT, n.d)
In the context of Generative AI, image generation occurs when an AI system trained on images, uses the patterns and relationships it identified within the training data to create new images when prompted. (Goff, & Dennehy, 2023; UMA, n.d.)
Following the training of an AI model, inference is the process that occurs when an AI model, using its knowledge base, engages with new data with the aim of generating new content, making predictions and/or executing on a task. (UMA, n.d.; CTLT, n.d.)
The data that is used to train or prompt the AI models. (UofS, n.d)
Used in training for machine learning models, data is labeled or categorised to support supervised learning. The labels serve to instruct the models about what the correct interpretation or answer is. (Goff, & Dennehy, 2023)
Trained on a large number of texts, LLMs were developed to understand and make use of natural language to undertake a variety of language tasks. Through a process of prediction these models generate text that mimics natural language. (UofS, n.d.; Goff, & Dennehy, 2023; MU, n.d.; CTLT, n.d.; MIT, n.d; UMA, n.d.)
When the opportunities for skill development and learning are lost because of a reliance on and/or inappropriate use of Generative AI technologies. (UofS, n.d.)
A process of learning, where AI systems learn from data without the need for specific programming. (UofS, n.d.; Goff, & Dennehy, 2023; UMA, n.d.)
A set of instructions given to the AI by the developer. These instructions seek to establish the boundaries in which the AI should operate and set the rules and tone of engagement the AI should abide by when engaging with users of the AI model. (MIT, n.d.)
The algorithms and computational structures that underpin a Generative AI system. These algorithms and computational structures enable Generative AI to learn patterns and relationships, and generate new content. The neural networks and parameters of each model, alongside its training data, determines both its abilities and inabilities. (CTLT, n.d.)
The metrics used to assess how well a given AI is performing. (UMA, n.d.)
An AI model that can analyse and interpret multiple modes, such as video, audio, text and images, and create multimodal outputs (MIT, n.d.)
A subfield of computational linguistics and artificial intelligence, which seeks to enable AI systems to analyse, interpret and respond meaningfully to human language. (CTLT, n.d.; MIT, n.d.; UofS, n.d.; UMA n.d.)
A mathematical system, inspired by the human brain, that can learn through the analysis of patterns and relationships in data. These computational models consist of connected neurons (also known as nodes or layers) that process and share information and strengthen connections between one another. (MIT, n.d.; UofS, n.d.; UMA, n.d.)
A process in which an AI model captures irrelevant patterns and information that is then used in its process of prediction. This results in poor content generation. (UofS, n.d.)
Internal to an AI model, parameters are the numerical values that are established when an AI model is trained on data. Parameters can be finetuned and adjusted to improve the model's performance. Parameters underpin how the model processes data and produces outputs, and they ultimately inform the quality of the model. (MIT, n.d.; CTLT, n.d.; Belcic and Stryker, 2025)
Used for forecasting, these models identify patterns within data to make predictions on results, trends and happenings. (UofS, n.d.)
An input that seeks to trigger, shape and inform the generative output created by an AI model. (CTLT, n.d.; UMA, n.d.)
The practice of developing input prompts that are structured to capitalise on how AI models optimally function and on the model's capabilities. Prompts help to guide AI models and influence the type of output received. (CTLT, n.d.; MIT, n.d.; UofS, n.d.; UMA, n.d.)
An AI training method that sees a model optimise its decision making by receiving feedback, rewards or punishments based on the quality of its decision making. Human interaction is central to this learning process. (MIT, n.d.; UofS, n.d.; UMA, n.d.)
RAG occurs when a generative model (like a language model) draws upon external data sources, such as materials provided by the AI user, and generates an output that includes content retrieved from the external dataset. (MIT, n.d.; CTLT n.d.)
Represented as a graphic depiction, these networks map semantic relationships, making apparent complex relationships, patterns and hierarchies found in a given dataset and can improve the capabilities of natural language processing. (CTLT, n.d.)
A technique where labelled data with clear input and output pairs is used to train a model so that it learns to map an input to an output. (UofS, n.d.)
A parameter that determines how creative or expected an AI model's output is. Higher temperatures lead to increased variability and less predictability, whereas lower temperatures produce more anticipated results. (CTLT, n.d.; MIT, n.d.)
Small units of data used by AI models to enable processing. For example, in natural language processing, tokens may stand in for a word, parts of a word or even individual characters like a full stop or exclamation point. (UMA, n.d.; MIT, n.d., CTLT, n.d.)
A process where an AI model uses machine learning to learn to complete a task. In this process a training dataset and generated outputs are used to help the model establish and adjust its internal parameters to improve performance. (CTLT, n.d.; Goff, & Dennehy, 2023)
A critical aspect of machine learning, training data is a dataset used within an AI model to teach it and allow it to refine its internal parameters. The quality of the dataset used for training impacts on the quality of the AI model's performance and outputs. (Goff, & Dennehy, 2023; UMA, n.d.; UofS, n.d.)
Used in machine learning, transfer learning occurs when learning obtained from one task or in one domain is applied in a different context. (Goff, & Dennehy, 2023)
An AI model that processes sentences in parallel rather than in sequence. This enables these models to identify relationships between words in sentences regardless of how far apart their position is from one another. Transformers can also ascribe different weight to different parts of the data, enabling these models to process the contextual relationships found in language. (MIT, n.d.; CTLT, n.d.)
Underfitting occurs in the machine learning process when the patterns and relationships in training data are not identified by the model. This causes the model to perform poorly when working with training and new data. (UofS, n.d.)
Data that has not been labeled or categorised for an AI system. Unlabeled data is often used within unsupervised machine learning. (Goff, & Dennehy, 2023)
A type of machine learning where an AI model learns from patterns and relationships within its training data without human oversight. (Goff, & Dennehy, 2023)
A process of assessing the machine learning of an AI model by testing the accuracy of its outputs when engaging with unseen data. (UofS, n.d.)
A concept that describes a situation where an AI model uses its broader training to make inferences about new data it has not been exposed to before or specifically trained on. (CTLT, n.d.; Goff, & Dennehy, 2023)
References
Belcic, I., & Stryker, C. (2025). What are Model Parameters? IBM. Retrieved from IBM website - Think Topics.
Centre for Teaching, Learning and Technology. (n.d.). Glossary of GenAI Terms. University of British Columbia. Retrieved from University of British Columbia website.
Gergmann, D. (2024). What is a context window? IBM. Retrieved from IBM website - Think Topics.
Goff, L., & Dennehy, T. (2023). Toolkit for the Ethical Use of GenAI in Learning and Teaching. UCC Skills Centre. (AI)2ed Project. This work is licensed under Attribution-Non Commercial 4.0 International. Retrieved from Creative Commons.
Holdsworth, J., & Scapicchio, M. (2024). What is deep learning? IBM. Retrieved from IBM website Think Topics.
Jonker, A., & Rogers, J. (2024). What is Algorithmic Bias? IBM. Retrieved from IBM website - Think Topics.
Maynooth University. (n.d.). GenAI and My Learning: GenAI Glossary. Retrieved from Maynooth University website.
MIT Sloan Teaching & Learning Technologies. (n.d.). Glossary of Terms: Generative AI Basics. Retrieved from MIT website.
University of Maine at Augusta. (n.d.). Generative AI Glossary. Retrieved from University of Maine at Augusta website.
University of Saskatchewan. (n.d.). Glossary of GenAI Terms. Retrieved from University of Saskatchewan website.
Except where otherwise noted, content on the LEAD section of this website is licensed under a Creative Commons Attribution 4.0 International licence.
- Introduction
- Responsible Use in Teaching, Learning and Assessment
- Generative AI Infringements
- Considerations for Grading in the context of GenAI
- Key Terms




